This post is a continuation of a series, the first part is here, please read it before going forth.
This time I’m looking at performance of the 9 algorithms.
I performed the test on 4 computers:
Pentium D 805 @ 2.66 ghz
Windows XP x64
Gcc 4.5.2
Atom Z530 @ 1.6 ghz
Lubuntu 11.04 386
Gcc 4.5.2
Core2 Duo E4400 @ 2 ghz
Windows XP
Gcc 4.5.2
Phenom 2 X4 955 Black Edition @ 3.2 ghz
PC-BSD 9.0 x64 beta 1.5
Gcc 4.5.2
I failed to port the code to BSD on time, so I tested a Windows executable via wine. It shouldn’t have a measurable impact.
I tested the same 2 datasets as before with 4 KB sector size and block sizes of 8 KB and 128 KB.
All test were single threaded.
I’d like to start with noting that synthetic benchmark that would compare performance on a filesystem with a particular compressor would be a much too big task, that’s not what I’m trying to do. I’m measuring only performance of compressors in a setting that closely resembles work of filesystems like described in the previous post.
To give you impression of what are the speeds I’ll say that the fastest measured was 367 MB/s (Phenom, lzo 1x_1, TCUP, 128k) and the slowest – 1.1 MB/s (Atom, lzo 1x_999, SCC, 128k). From now on I’ll be talking about more abstract, but also more useful performance metrics.
First, MB/s is bad because it varies so much between CPUs. I wanted to make some average over different systems to avoid talking about 4 sets of very similar data. So I took zlib -9 as the baseline and measure performance as ‘how many times is it faster than zlib?’. This gives similar figures on all CPUs. Though not the same. Averaging is a simplification and I think it’s good for this post, but I encourage readers who want deeper insight to look at a spreadsheet attached at the end of the post.
So the first chart for you, performance relative to zlib -9, averaged across all machines.

As you can see, there are 2 groups of codecs, 5 fast and 4 slow ones. I didn’t include anything in the middle because preliminary testing of over 50 different codecs / settings didn’t show anything really interesting in there and the charts from the previous post looked much more cramped even with 1 more codec.
Now there’s a matter of efficiency. The most popular approach is charting compression speed vs. size ratio for different codecs. If one is both stronger and faster than another, then it’s better. If they are close in one metric, but distant in the other you can draw conclusions on efficiency too. I propose a scheme that’s more accurate and more suitable for decompression measurements in this test.
I propose to replace raw speed with speed of reducing dataset, i.e. codec 1 saves 5 MB/s until the size reaches 40% of the original. It’s more accurate because when a codec 1 gives half of savings of codec 2 in 2/3 time, it’s not comparable using the first metric, but looses with the latter – which is good because if you take codec 2, compress half of the data and leave the other half uncompressed, you have something that’s just as strong as codec 1 and faster by 1/6. Also, in cases when it doesn’t show a clear winner, it brings codecs with potentially similar characteristics closer together making it easier to do evaluations.
So we have a great way of charting compression performance, but decompression is problematic.
Like I said in the previous post, data is split to blocks that are compressed independently. If a block has good enough compression ratio, filesystem stores it compressed, otherwise – uncompressed. The problem is – for each codec, the data it will eventually decompress is different. Not only amount of data decompressed differs, particular blocks that get decompressed differ too. Here, raw speed comparisons don’t make sense. A stronger compressor will almost always loose. Saved MB/s (decompression seconds) works better. I’m not very happy with this metric, but it’s the best that I see. Also, comparing different decoders on different data is bad, but that’s how it works in real world.
So the most important charts. I divided data into 2 sets, 8k and 128k blocks and averaged over other parameters (CPU, dataset). Performance is relative to zlib-9 again.



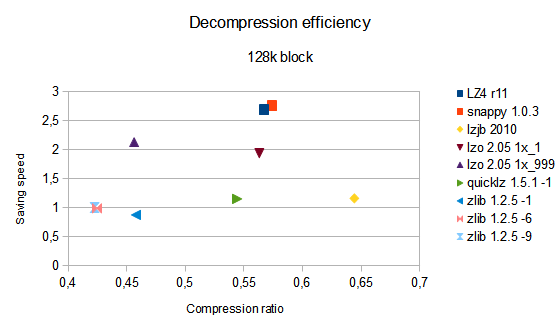
Conclusions?
But there was one more claim about LZJB being good for the task. It has some smarts that detect incompressible data and resigns much quicker than competition.
There was a test that verified it positively. My results?

Well, different. I verified that what I use is indeed the same code that’s in Oracle repository. Looking closer at the data, in the test performed by Denis and erdgeist, LZJB speed increased by ~30%. In my it decreased by 3-33%. I don’t know the reason.
Furthermore, their test shows that LZO doesn’t have such speedy way of dealing with incompressible data. In my it does. Well, there are like 20 versions of LZO and in preliminary tests I chose one that has this feature.
Also, there are such modes in other codecs too (not in zlib) and Snappy on Phenom does a whooping 1.8 GB/s.
I promised to give you a spreadsheet with more data. It contains raw logs from my benchmark and a ton of statistics. If you want to learn more, it’s a highly recommended reading. Click.
Benchmark sources.
So do we have enough data to answer the question of what is the best codec for filesystem compression? No. There are at least 2 other important questions:
-How do they work with different compilers? Linux uses GCC. FreeBSD uses Clang. Solaris, I think, SunCC.
-How do they scale with multiple cores? Filesystem compression is inherently scalable but are these algorithms?
TODO.
Update:
Yann Collet, the author of LZ4 contacted me and suggested to use the other of 2 decoding functions, which should be faster. I will test it soon.
Update2 (16.09.2011):
In the meantime there were several LZ4 updates and today Snappy got performance improvements too. I’m glad I didn’t rush to test stuff because it would be obsolete in 2 weeks!
Anyway please note that the contents of this post are outdated and should be taken with a grain of salt.


Thank you for taking the time and effort! The fact that your results vary from those performed by others (Denis&Erdgeist) should leave some area for an interesting debate, but all the evidence (raw data, test system, etc) is there to reference, so feedback as to why lzjb is actually slower than was initially tested should be interesting. Considering that Nexenta uses the lzjb compression algorithm as standard, I’m now considering testing with the gzip (their other supported algorithm) to see whether there will indeed be a performance (loss according to Nexenta) and to determine the compression difference. Considering the time it’s going to take me, I’m not sure I should be thanking you… 😉
From the gzip.org’s FAQ: “The gzip format was designed to retain the directory information about a single file, such as the name and last modification date. The zlib format on the other hand was designed for in-memory and communication channel applications, and has a much more compact header and trailer and uses a faster integrity check than gzip.”
According to Nexenta, lzjb is “optimized for performance while providing decent data compression”… now you’ve got me thinking…
Comment by Kyle — November 10, 2011 @ 5:32 pm