There are quite a few established image compression benchmarks, but none are centred around images that you can find on the web. And as Google recently released their new contender in the space, I thought that such test would be useful.
Competitors:
I tested all compressed image formats with reasonable popularity and some more:
Webp Lossless – the star of today’s show. Extremely slow, but supposedly strong compression and fast decompression.
Optimized PNG – an old and weak, but hugely popular image format. I optimized the images with the scheme that I use for myself:
-
deinterlacing
-
pngwolf
-
pngout /s0 /f6
-
deflopt
-
defluff
I find it to be the strongest scheme that’s worth using, though clearly some disagree and make stronger but much slower ones.
BCIF – the state of art encoder with fast decoding. Nobody uses it, but it works well.
JPEG2000 – The second most popular file format in the comparison, far from the first and from the third. I wondered whether to include it, because its decompression speed is bad, it’s not really in the same league. Still, I was interested how does it fare on web images.
JPEG-LS – even less popular than JPEG2000, but quite fast and in some tests it was overall very efficient. I used CharLS as the reference implementation. Again I had to use the splitting trick. Encoded
I considered testing FLIC too, but decided against it. Much like JPEG2000 it’s in a different league and unlike JPEG2000, nobody uses it. And it’s likely that it wouldn’t score great because it is implemented to compress photographic images.
I used the following program versions:
webpll version 2011-11-20
ImageMagick 6.7.3-8
pngwolf 2011-04-08
pngout 2011-07-02
deflopt 2.07
defluff 0.3.2
BCIF 1.0 beta for Windows
BCIF 1.0 beta Java (when the previous one crashed)
Kakadu 6.4.1
Loco 1.00
Test Data:
I downloaded all PNG images from Alexa top 100 sites and everything 1 link away from them. I didn’t block ads. This yielded ~350 MB of images with average size of just over 17 KB. That was too much, I wanted ~100 MB. So I chose 6000 randomly and got a dataset of 105.2 MB.
Next time I would do it better though. In the dataset there are a few series of very similar images, throwing away almost 3/4 of the dataset couldn’t eliminate them and I think that spidering the entire top 1000 would be better. Or maybe first-page results of top 100 Google searches would work even better? Either selection is biased anyway, it’s hard to come up with something that isn’t.
The files take 105.2 MB as PNGs and 486.3 MB decompressed to PPMs.
The smallest image has 70 bytes, the largest 1.8 MB. The average size is 18 KB and the median – 4.3 KB.
47.4% use transparency. Or rather – have transparency information embedded. In quite a few cases the info says just that the image is fully opaque, which takes some space and does nothing.
I wanted to determine how many of them came optimized. But how to tell them from the rest? I guess that the best way is to see whether my optimization gets significant savings. What is significant? At first I decided: 2%. Under this definition, 9.2% of images came optimized. But later I decided to sort files by compression ratio achieved by optimization and plot compression ratio against percentile of files.
The results are below:
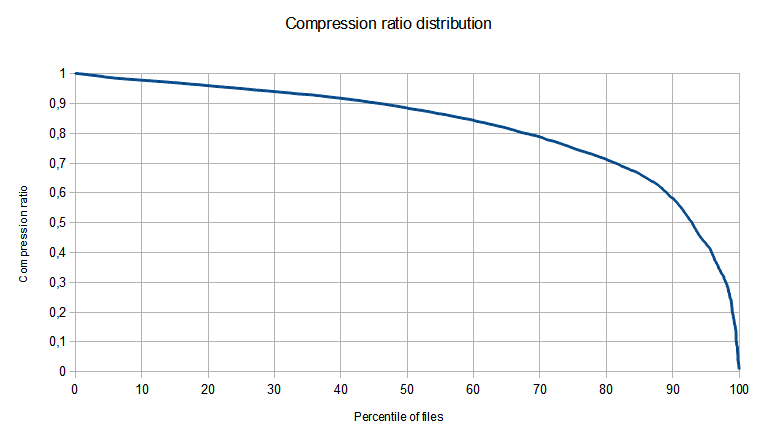
As you can see, the line is quite smooth, there is no clear divide between files that came optimized already and those that didn’t.
You can also note that compression ratio goes almost down to 0 (more precisely – to 0.01004). On one file recompression saved almost 99% of initial size, on 11 – at least 95%. Quite a lot, I think.
Problems with making the test:
It’s sad to say, but the state of image manipulation software and partially with the ecosystem in general is just terrible. Problems?
1. There is no standard image format. When it comes to viewing, there is no problem. But with format conversion, there is. Some encoders require PNG input. Some BMP. Some PNM. And these formats are not compatible with each other. The limitations that hurt me with this test were lack of support for transparency and for bit depths greater than 8 bits per colour per pixel.
2. Encoders have limited support for input file formats. Sometimes its bugs, sometimes just lacking features, but I’ve had problems with, I think, 3 programs because of it.
3. Encoders don’t fully support their target output. For example, nconvert can’t compress to JPEG2000 losslessly and OpenJPEG JPEG2000 encoder doesn’t support transparency.
4. Image conversion tools are limited or buggy. There were 3 image conversion tools that I tried, ImageMagick, Nconvert and ImageWorsener. The last one wasn’t really useful because it supported ony BMP output and only for non-transparent files. Both ImageMagick and Nconvert would silently corrupt data from time to time..
5. The worst of all. I found no image comparison program that would work correctly. Tried 2. ImageMagick and Imagediff. Both produced both false positives and false negatives. There are 1000s of others out there, but seemingly nothing that would allow batch comparisons. So I worked with terribly buggy programs that frequently corrupted my data and I couldn’t reliably detect whether they had luck to produce correct results or not. I spent a lot of time doing different tests to assess correctness and whatever bug I found – I worked around it. But there may be more. I don’t know. It’s really disheartening.
To give you a sense what I went through, a JPEG2000 transparency story:
OpenJPEG doesn’t support transparency at all.
Nconvert doesn’t support lossless mode at all.
ImageMagick corrupts data when used this way.
Jasper accepts only bitmaps. But not transparent ones produced by ImageMagick.
Kakadu accepts only bitmaps. But not transparent ones produced by ImageMagick.
Jasper doesn’t accept bitmaps created by Nconvert either.
But Kakadu does!
Nconvert corrupts data with such translation.
So after a lot of work, I didn’t find a way to make it work. I decided to use (unreliable) verification of Nconvert’s work and when there were problems – I split each file into 2; one contained only colours and the other only transparency data. Compressed them independently and summed the sizes.
I did the same splitting trick with formats that don’t support transparency, JPEG-LS and BCIF.
Also, none format other than PNG supported 64-bit images. Or rather – JPEG2000 supports them, but Nconvert doesn’t. With such images I added a (unoptimized) PNG size to the listing of each codec (except for optimized PNG, which is the only that got any savings on these images).
Performance:
I didn’t measure performance. The data was quite large and I couldn’t afford leaving the computer exclusively for compression and using it while compressing skews the results. So the only strong data provided is compressed size. But to give you some idea of what’s going on, webp took over 4 days and nights of CPU time. PNG optimization half as much. All others did their jobs in minutes.
Results:
First, some numbers:
Optimization compressed the data to 84.1%
Webpll to 65.7%
BCIF to 93.7%
JPEG2000 to 110.8%
JPEG-LS to 115.8%.
Quite interesting. BCIF, JPEG2000 and JPEG-LS all beat PNG by a significant margin in all tests that I’ve seen before. And now they got beaten by it. I guess there is a merit in naming the file format “Portable Network Graphics”.
By looking at fragmentary test results of other people I expected webpll to be rather pale in comparison, but it leads the pack with a big margin. 21.9% over the second, to be precise.
Let’s look into more details.
One picture is worth 1000 words:
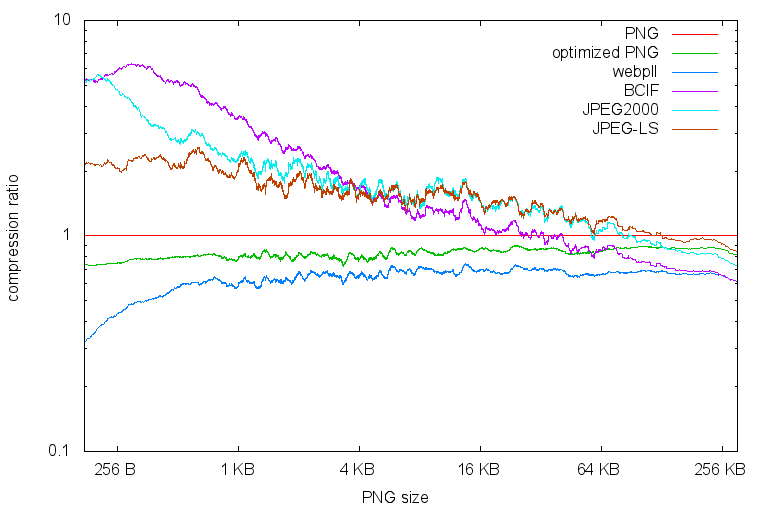
But sometimes needs explaining. Oh well.
The files are sorted by their original sizes, on the left are the small and on the right are the big. Each line represents a compressor. The y-axis is compression ratio, the smaller the better.
Both axes have logarithmic scales. Also, to make it readable I applied a low-pass filter to the data.
As you can see, except for files < 1 KB, the distance between optimized PNG and webpll is quite constant. The other formats are very bad with small images and improve all the way when sizes grow. At roughly 256 KB BCIF is the strongest of the pack, ex-equo with webpll.
Part of the disconnection between webpll and the rest is file format complexity. Let's look at the smallest image size that I got in each format:
webpll: 6 B
PNG: 68 B
JPEG-LS: 38 B
JPEG2000: 287 B
BCIF: 134 B.
When compressing 1-pixel files, 280 B overhead is something.
Though it should be noted that HTTP protocol has some overhead too and differences in performance would be much lower (I guess that practically none). Still, JPEG2000 overhead (assuming it's constant over all files) adds to over 1.6 MB over the entire dataset.
ADDED: Correction, my guess was wrong. People who know the stuff better then I do said that despite HTTP overhead, the minor changes still matter.
You can download full results here.
Summary:
There are 2 classes of image codecs, those that are web centric and that are not. The web-centric care little about speed (you can find some really extreme PNG optimization scripts), but are much stronger on web data. Wepb lossless worked well, it’s very slow but significantly stronger then anything else.